
Genetic variant database
Genetic variant database is a fundamental infrastructure for large-scale whole-genome/exome sequencing projects. It is important not only for rapidly extracting genetic variants and mutations for the samples of interest, but also for correctly interpreting mutations using population features such as allele frequencies and population structures. Our solution is the unique as it stores homozygous reference and missing calls to significantly enhance the accuracy of allele frequency estimates.
Our pipeline based on a MapReduce framework has already produced a genetic variant database storing the genotypes of 7000 whole-genome sequencing samples and enabling genotype queries and allele frequency computing within minutes.
Pipeline design
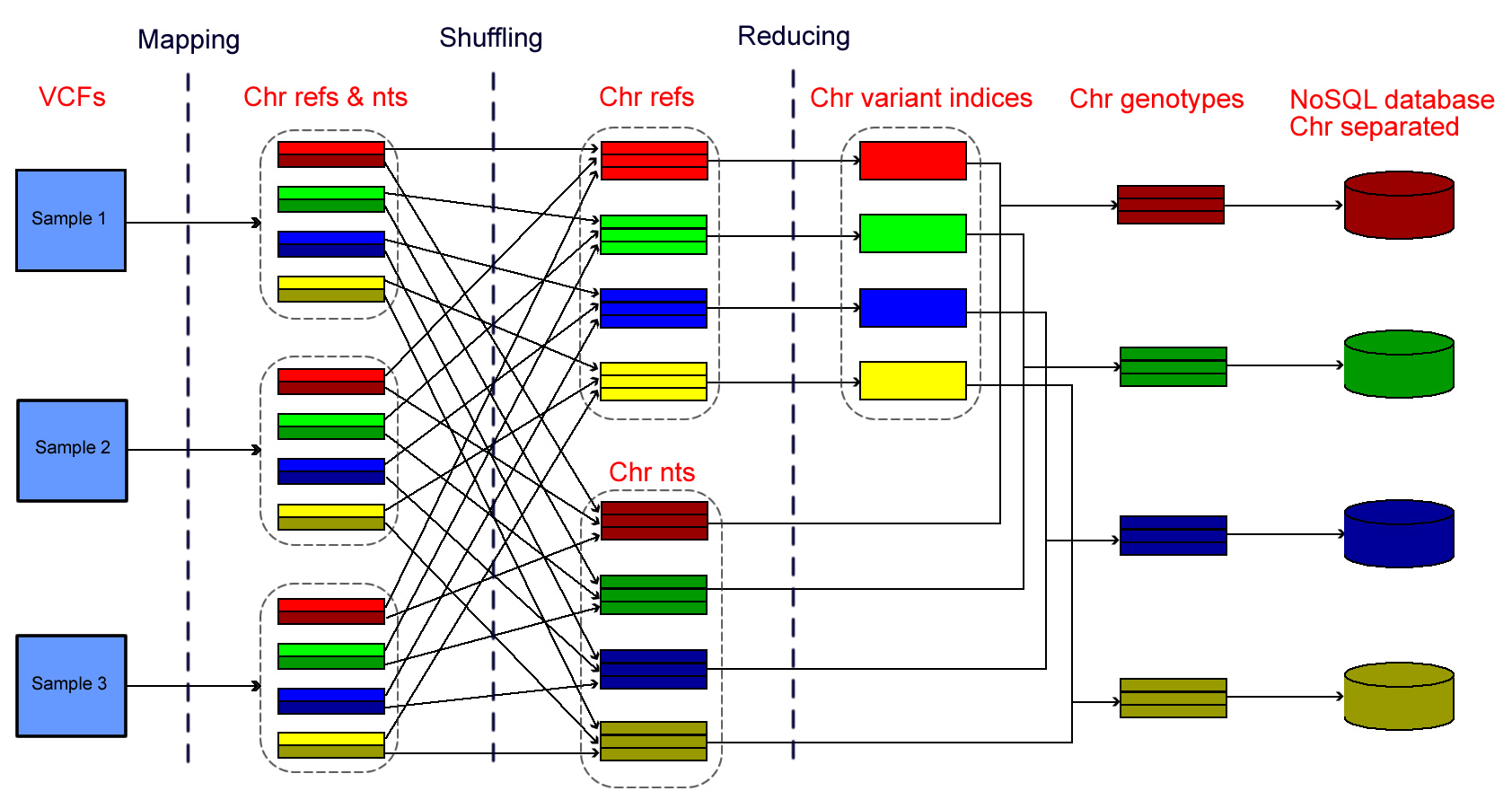
Database construction
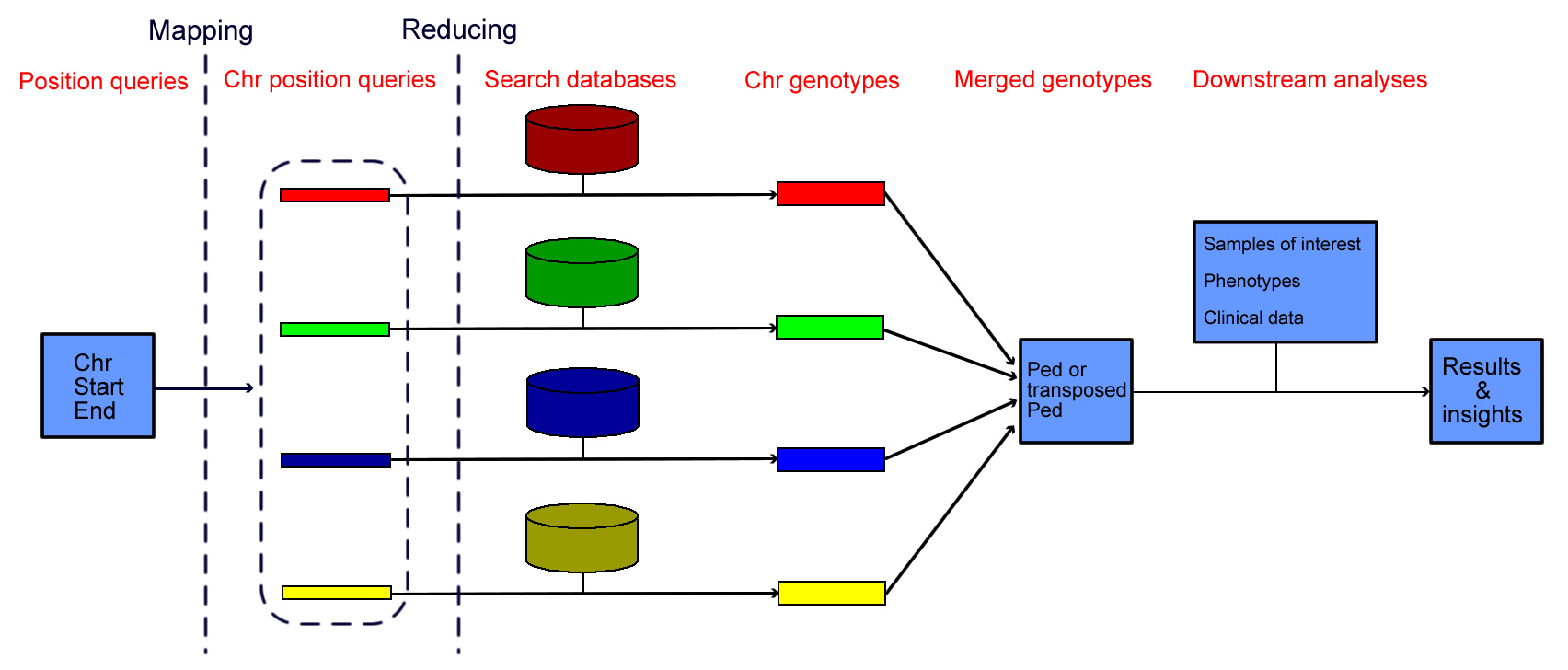
Database queries
Advantages of our solution
- The database construction can be realized on any Linux clusters or commercial cloud services depending on the preference of clients.
- Input VCF files are processed on the basis of individual chromosomes and the database stores genotypes as text files.
- QC is performed prior to the database construction to minimize junk information within the database.
- Homozygous reference and missing calls are stored in the database, rendering accurate allele frequency computing.
- Genotypes of all samples are stored as sorted genotype matrices (ped or transposed ped format), with separate index files.
- The database is searched by Perl/C++ programs. For database queries, it is not required to use clusters or large-memory computers.
- Diverse downstream tools can be directly applied to the outputs of the database queries so as to rapidly generate analyses and insights.